
独家专访Feeling AI创始人戴勃:我想让世界模型更有“活人感”|甲子光年

Feeling AI要补齐的,是世界模型最被低估的一块拼图——动态交互的模型层能力。
作者|周悦
编辑|王博
《上古卷轴5》发售已经超过十四年,但有一个细节一直卡在Feeling AI创始人戴勃脑海里。
玩家在游戏里已经是龙裔、战友团队长、盗贼公会会长,走南闯北成就了一番事业,回到雪漫城,城门口的守卫还是不认识你。
“按道理你已经是世界有名的人了,他的对话逻辑应该要有变化的。”他说。
更让他出戏的,是战斗里的NPC:“打多了,能发现规律,甚至可以利用规律,知道它会在哪个时刻过来,然后耍一道帅气的镰刀背刺。”
戴勃把这种落差叫做“缺乏活人感”。不久前发布的MemBrain(记忆)和CodeBrain(规划),正是为了解决这个问题。
但这两个项目并非刻意设计,而是在工程和产品化中催生的结果。
Feeling AI最初想做的是动态交互世界,用户和AI共同身处一个持续变化的世界,每个角色有记忆、性格和独立的行动逻辑。
在最初的尝试中,大部分开发者和用户都不排斥这个方向,“想法很好”,但彼时技术托不住产品效果。NPC能接话,但不能把前情自然带到下一轮反馈;能生成几步计划,却无法在变化的世界里连贯行动。
戴勃说,核心问题在角色的记忆和规划能力上。现有方案不够用,团队索性自己动手,做出了负责记忆的MemBrain和负责规划的CodeBrain。跑完Benchmark发现性能高出业界方案,在全球基准中都取得领先表现。“团队一致觉得应该开源,因为总有更多人会碰到类似需求。”
“CodeBrain和MemBrain,就是为了活人感而生的。”戴勃告诉「甲子光年」。其背后更重要的目标,是为世界模型配上一个原生的Agentic大脑。
从玩家执念,到一头扎进的底层技术,戴勃的履历足够支撑这种跨度。2014年他从上海交大ACM班毕业后进入香港中文大学读博,开始深耕生成式AI方向的研究,从语言、图像到动态视频生成和3DGS,研究成果横跨多种模态。
戴勃曾任职于新加坡南洋理工大学和上海人工智能实验室(AI Lab),创办的Feeling AI已完成两轮超亿元融资,是国内最早探索世界模型和3D动态交互的团队之一。

Feeling AI创始人戴勃,图片来源:受访者
近期在接受「甲子光年」独家专访时,戴勃首次完整复盘了这条隐秘的路线:一个游戏里的老问题,如何催生产品、开源项目,并最终指向了他们对世界模型的判断。
同时,戴勃还透露,Feeling AI即将发布并开源MemBrain1.5和CodeBrain。前者在多项指标超越SOTA,并提供了可直接体验的可视化Demo;后者技术指标领先,且大幅降低使用成本,支持多语言、Monorepo感知和零框架耦合等功能,并将20个底层LSP操作整合为大模型所需的工具。
1.记忆的“中庸之道”
AI究竟该拥有怎样的记忆?
戴勃的判断简单而直接:“完全不记得肯定不行,但什么都记得一字不差也很奇怪,人的记忆需要中庸。”
重要的事能保留下来,细节会随时间模糊,旧经历会自然融入新反应,这才接近真实的人的状态,而不是一个什么都存、随时精准检索的数据库。
目前,智能体记忆(Agent Memory)的技术路线尚未收敛,现有的解法都难以呈现这种“中庸”的活人感。
一派偏向图结构,将知识拆解为实体、关系和事件,依靠图算法检索和推理。优点是结构严密,但很死板;另一派则更接近OpenClaw这样的纯文本(Markdown-first)路线,把记忆写成语言模型最熟悉的文本格式。虽然亲和语言模型,但将海量信息的判断全权交由模型发挥,稳定性又无法保证。
为了实现“活人感”,MemBrain避开了这两条老路,做了三处底层创新。
第一,打破线性流程。传统记忆系统的调用顺序是写死的:检索、总结、回答。但人的记忆是随机的、跳跃的。“我说着说着突然想到了什么,然后说法又变了”,戴勃解释说。为了模拟这种动态,MemBrain把记忆的抽取、整合、提取交给不同的子智能体(Sub-Agent)各司其职、自主协调,提升灵活性。
第二,让语言模型真正参与推理。许多主流方案依赖图结构存储知识,但在检索时,图算法与大语言模型之间存在着难以逾越的范式差异——前者在图节点上做复杂运算,后者则是线性的Next-token(下一个词)预测。“图算法在算的时候,语言模型只能站在旁边看着,帮不上忙。”为了解决这个问题,MemBrain改用了与语言模型更亲和的组织方式,让模型直接参与记忆处理,而不是干等图算法出结果再接收。
第三,严控时间戳。“昨天”“上周三”“3月24号”……在自然语言中,同一个时间点有无数种模糊的表达。如果不做统一的标准化处理,事件的发生顺序极易陷入混乱,记忆的溯源更是无从谈起。MemBrain将时间戳严格精确到秒,并引入自适应实体树算法,优化实体、事件与关系在时间轴上的组织结构。
这套改法有一个共同的出发点:不把AI记忆做成一个更精准的检索系统,而是让它更接近人的记忆运作方式,有主见、有顺序感、能自己判断什么重要。
今年2月,Feeling AI正式开源了MemBrain 1.0。在LoCoMo和LongMemEval两项主流测试基准上,MemBrain 1.0分别以93.25%和84.6%的准确率实现SOTA。而在考察隐性画像捕捉能力的PersonaMem-v2测试基准上,MemBrain 1.0以51.50%的准确率超越现有方案。
但真正能验证“活人感”的,是那些更逼近人类能力的测试。
以Hugging Face广受关注的Knowme-Bench基准为例,该评测要求模型不能只做基础的精确记忆抽取,而是必须基于庞杂的记忆内容,完成深层分析与复杂推理。
结果显示,Membrain 1.0在Knowme-Bench基准测试高阶认知任务中表现出了明显优势。特别是在难度登顶的Level III级别(涵盖心身交互与专家级心理分析的T6、T7 两个子任务)中,Membrain 1.0的成绩比现有最高纪录提升了300%以上。
「甲子光年」独家获悉,Feeling AI即将发布并开源MemBrain1.5。“除了各项指标超越了之前的SOTA,还做了一些可以让用户直接尝试的Demo和方便开发者测试使用的可视化工具。”戴勃介绍。
MemBrain解决“记住什么”,CodeBrain处理“接下去怎么做”。
今年春节前,CodeBrain-1搭载GPT-5.3-Codex底座模型在衡量Agent真实工程能力全球权威基准Terminal-Bench 2.0榜单上冲到72.9%并跻身全球排行榜前列,成为榜单前10中唯一的中国团队。
规划能力在现有Agent系统里并不罕见,技术深水区在于,当任务复杂度呈指数级上升后,执行的成功率还能否稳得住。“如果规划了三五次,成功率只有20%,你很难说这是个好的CodeBrain。”戴勃强调。
为此,CodeBrain在架构中引入了一层极重的校验模块(Verification),模型在生成规划链之后,必须先对该计划的可行性进行自我验证与倒推,把复杂任务的执行成功率拉上来。
戴勃说,“CodeBrain一样也会在几天后开源,除了技术指标的领先,CodeBrain还大幅降低了开发者和付费用户的使用成本。”预计开源的版本中还会支持多种供开发者灵活使用的功能,比如多语言支持、Monorepo感知和零框架耦合等,还直接将20个底层LSP操作整合为大模型实际需要的工具。
2.缺失的拼图
但“活人感”不只是记忆和规划的问题。
即使NPC记住了你、规划出了下一步,如果它的动作还像机器人,转身的角度生硬,出拳的节奏固定,走路没有惯性,仍然没有活人感。记忆和规划解决的是“想什么”,动作本身才是活人感最直接的载体。
要理解这个问题,需要先看戴勃对世界模型的拆解。
在他看来,世界模型不是一个单一的模型,而是三层结构。最上面是逻辑层,处理记忆和规划,解决“我想干什么”——MemBrain和CodeBrain属于这层。最下面是表现层,负责3D环境、视频生成、交互界面,把结果呈现出来。
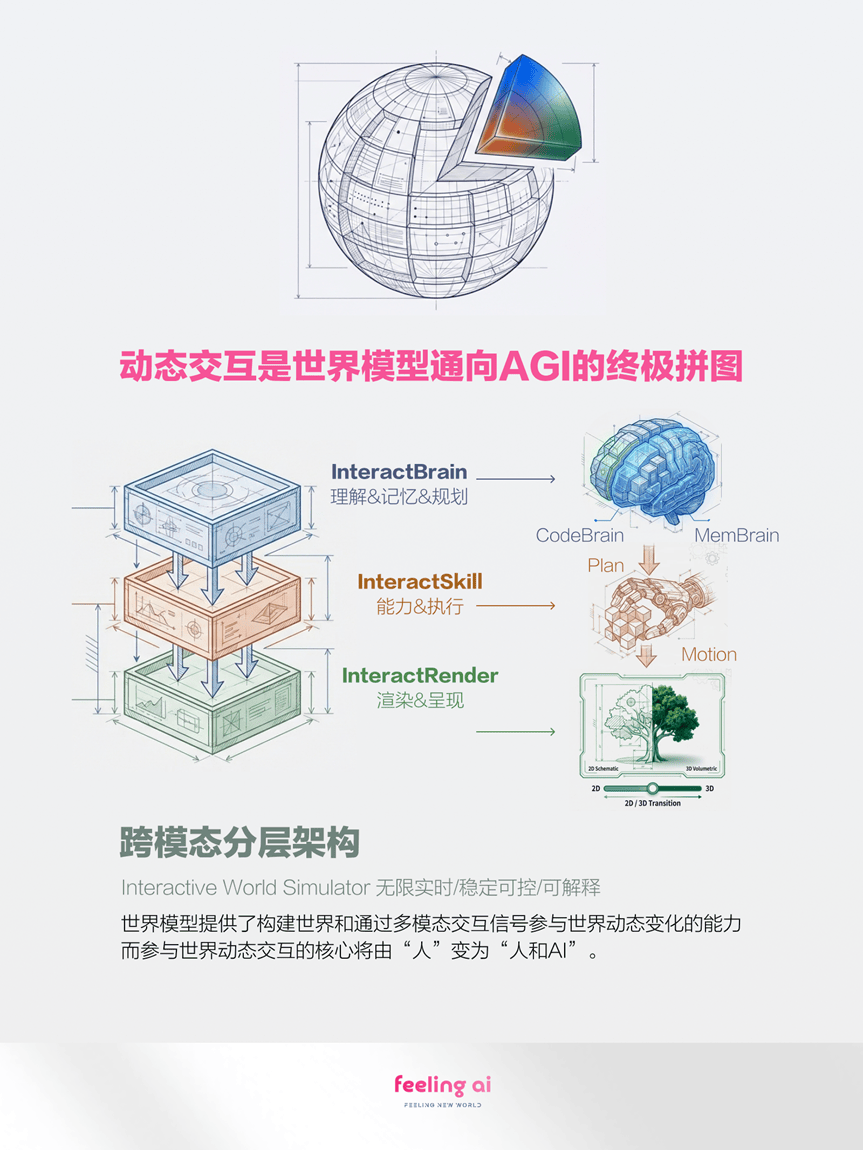
Feeling AI动力学世界模型架构图,图片来源:Feeling AI公众号
夹在中间的是动态层,负责把“想法”真正变成“行为和表现”。这正是他认为整个行业最缺的那块拼图。
他用“口渴喝水”来解释三层的关系:想到要去喝水是逻辑层;伸手拿杯子是动态层;动作呈现在屏幕里是表现层。少了中间那层,逻辑和表现之间就是断的。
业内关于世界模型的讨论已经很多,各方侧重点不同。有人专注静态的3D环境表征,以李飞飞的World Labs为代表;有人倾向于在压缩隐空间内做核心状态预测,以杨立昆(Yann LeCun)的AMI团队为代表。
“但我们觉得,中间还缺一个东西——动态。”戴勃说。
动态层的难点在于,现有的生成模型本质上还在做“下一帧预测”,把过去若干帧作为输入,靠概率去猜下一帧。这个黑盒学到的是视觉表观的相关性,而不是物理因果。一旦拉长推演时间或进行实时交互,误差便会积累,出现动作漂移、接触错位等问题,越来越像在模仿运动,而不是真正掌握运动规律。
戴勃的解法,是先把围绕以人为中心的“运动主体”和与人类运动息息相关的“交互客体”找到合适的结构表示,再让模型去学它们之间如何相互作用。换句话说,把物理先验作为模型的底层基础,而不只是外部约束。
当模型具备了内在的物理约束,推理过程就不再是黑盒。“它不是一个black box,你知道它背后是什么,就不会担心下一个时刻动态又不对了。”据戴勃透露,在这套世界模型架构下,团队已经取得了一些里程碑式的进展。
通过这个全新架构的动力学世界模型,在3D原生的结构下通过原创的IKGT算法(Interactable Kinetics Grounded Transformer),实现对人类运动交互的生成与状态预测。模型首次在CPU上跑出300FPS的响应速率,连续运行40分钟也不会出现明显的动作漂移,且模型通过实时推理达到了100%的状态重置和纠偏,鲁棒性极强。
3.四年四轮验证
把物理先验嵌进大模型,不能停留在理论层面。在MemBrain和CodeBrain出现前,戴勃和团队在动力学这条路上已经走了四年,且每一轮都在主动拉高难度。
2022年,从水和木头起步。用神经网络预测粒子系统的动态时序交互,取代传统图形学的物理公式求解。结果显示,无论将方形木块换成圆形或者其他形状,或是改变水量,同一个神经网络都能正确预测,泛化性显著。
2023年,他们主动把难度提高一个层级,验证多层衣服的可能性。当时公开研究多停留在单层衣物,戴勃觉得这个难度不够,直接处理外套内搭毛衣的接触与摩擦。“我们觉得,不管一件还是几件衣服,应该用同一套方法处理。”测试表明,无论是层数增加、拓扑结构改变,还是人体动作切换,模型都保持了稳定。
2024年,团队尝试了另一种难度维度的跨越,压缩训练数据。如果训练数据只有一块四方形布料的视频,模型能否推演至由同材质、任意形状的衣服,在不同人做不同动作时的动态变化?
结果是可行的。“从F=ma出发,因为布料和同种材质的衣服遵循同样的动力学先验,学会布料怎么动,自然就能泛化到更复杂的情况。”戴勃解释,动力学先验给了模型基础,它就不需要那么多数据了。
2024到2025年间,从仿真系统延伸至真实自然环境。团队从现实中重建花草树木,让模型学习它们受力后的动态。“只观察过它在某种风力下的晃动,但学到了它的动力学模型。用手拨它,把花压到很低,松开之后它会弹,会自己在那晃——这个运动轨迹是合理的。“戴勃形容观察到的变化。
从流体、固体到柔性物体,从极少数据到真实场景,四轮下来,每轮比上一轮难,每轮都对了。“一次、两次、三次、四次验证了这一套技术路线,就非常信了。”戴勃说。即使在外界看来这条路属于非共识,团队也没有换方向,“非共识有压力,但也是机会。”
4.通往“绿洲”的现实路径
“以终为始,求上得中。”戴勃用这句话解释Feeling AI的底层逻辑,用工程和产品落地的硬性标准,反向倒逼模型能力的进化。
这条路不仅催生了MemBrain和CodeBrain,也让他看清了另一件事,在底层能力没到位之前,盲目的推进产品,精力只会消耗在无休止的打补丁上。
他打了个比方:在GPT-2的时代做应用,无论如何修补,能力天花板就摆在那里。与其勉强应付,不如先把模型推到GPT-3的水平,ChatGPT会自然生长出来。
“从产品导向去回答这个问题,本身就不够AI Native(AI原生)。”戴勃说这是创业以来最有价值的经验。
在他看来,算法出身的创业者总有一种惯性,相信算法是万能的,“有点唯算法论的意思”。但持续“求真”和“求证”的过程让他意识到,不是所有体验都能靠产品设计修补,哪层的问题就在哪层解决。
“用户体验不会为模型的能力找借口,但会消耗用户的热爱。”Feeling AI的定位由此清晰,一家做世界模型的基模公司。
正如语言模型催生了OpenAI这类基模公司,戴勃相信世界模型在Scaling到一定阶段之后,也会长出自己的原生应用。“但那是技术到位之后自然会发生的事,现在的重心应该放在技术本身。”
2023年,视频生成最火热时他没有选择沿着爆火的AnimateDiff继续往前走,2024年世界模型还只是个陌生的概念时,他在讲如何构建Real-Sim-Real闭环。
2026年,他认为:“现在终于有机会可以参与定义世界模型底层能力,这很AI Native。”
战术随之清晰,逻辑层离贴近现有大模型生态,成熟快,率先开源接受验证;动力学世界模型体量大、门槛高,现阶段重心在其规模化(Scaling)上。“我们现在要走的是从Transformer到GPT-3的那段路。”
数据是核心瓶颈。物理先验虽然降低了门槛,但Scaling到一定规模,绝对数量依然庞大。
Feeling AI团队自研从视频里抽取运动数据的算法,以“合成数据保量、真实数据保质”。目标是2026年下半年推出完成第一阶段Scaling的版本,并开放API,从而打通逻辑层、动态层和表现层。
戴勃把当前世界模型赛道比作“盲人摸象”,有人摸到鼻子,有人摸到腿,说的都没错,但都是局部。Feeling AI选择从第一性原理出发,主动思考如何构建底层基础设施:“动力学,或者说动态交互能力,一定是最核心的那块拼图。”
“如何融合这些局部找到最终答案,是整个行业长期的命题;而我们笃定从这个方向往里走,是因为觉得动力学最重要,也最被低估。”戴勃表示。
当谈及世界模型与具身智能。戴勃观察到,世界模型正趋向具身智能,相关仿真训练和数据公司也在寻求合作。但他认为,完整的世界模型架构,更可能先在游戏等互动内容中完成闭环,“那里会是数字世界与真实世界相连接的第一个试验场。”
采访临近尾声,当被问及这套“人与AI共创、自然演进”的愿景是否像电影《头号玩家》里的“绿洲”时,戴勃愣了一下,笑了:“这是创业最初的冲动,《头号玩家》里的‘绿洲’就像是一个暗号。没想到是你先说出来的。”
《上古卷轴5》里NPC那些套话,戴勃显然记了很久。现在他做的事,是从底层解决“活人感”缺失的老问题。不是多塞几句拟人台词,而是让角色真正生活在有记忆、会演化、互相影响的动态世界里。
从一块方形的布,到一朵受力回弹的花,再到实战催生出来的MemBrain和CodeBrain,这条路他走了四年,还没走完。
“这是一个比较长期的事情,”戴勃说,“但方向是对的。”
*参考材料:
1."Transformer with implicit edges for particle-based physics simulation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
2."Towards multi-layered 3d garments animation." Proceedings of the IEEE/CVF international conference on computer vision. 2023.
(封面图来源:AI生成)